Vassilis Hartzoulakis
ITEM
ANALYSIS IN THE KPG EXAMS
The KPG exam system
conforms to a number of norms that
secure the highest possible test
reliability and validity. Some of them
have already been discussed in previous
articles (e.g. oral examiner training,
script rater training, evaluation
criteria for the writing test,
assessment criteria for the listening
test etc.). This article will focus on
the criteria for the selection of items
in the reading and listening
comprehension tests and the subsequent
statistical analyses performed by the KPG exam team.
Designing and setting
up a test for the KPG exam battery is a
painstaking complex process involving a
number of stages. After the initial
design of a task and its related test
items, a small scale pre-test is carried
out; this provides feedback as to the
appropriateness of the task in terms of
content and language level. Items in a
task or even full tasks that do not fit
in the test content specifications or
the specifications for the test tasks,
as defined by the KPG examination board,
are either revised or dropped entirely.
This first round of
checks is followed by subsequent rounds
with associated revisions of tasks and
items until the criteria for content and
language level are fully met.scale
to an alyses carrieried out by the KPG
exam team.tems in the reading
Next, the selected items are piloted
with a sample of test takers bearing
more or less the same characteristics as
the candidates expected in the
actual exam.
The results yielded go through a series
of checks for the statistical
characteristics of the items. These
checks fall under the category of
“classical item analysis” (called
'classical' because it is based on
classical test theory) and include:
1.
a check for
the desired level of difficulty of the
item (referred to as “p” index),
2.
a check for
its desired discrimination power
(referred to as “d” index)
3.
a series of
checks for the performance of the
distracters and
4.
a series of
checks for the overall reliability of
the test.
Depending on the
findings of the item analysis, further
adjustments are made to ensure the
appropriate difficulty level for each
item (and consequently for the relevant
task) and the appropriate item
discrimination power (or in other words,
the item’s power to distinguish between
high achievers and low achievers). For
criterion-referenced tests such as the KPG tests, we usually follow a “rule of
thumb” of selecting items whose
difficulty index falls within a range of
p-values between .20 and .80 on a scale
of 0.0-1.0 (Bachman, 2004). Items below
.20 are considered “too difficult” (in
practice it means that less than 20% of
the test takers answered the item
correctly)and items over .80 (which in
turn means that more than 80% of the
test takers answered correctly) are
considered “too easy”.
When an item is found
to be “too difficult” or “too easy”,
then it is revised. For example, in
multiple choice items one of the
distracters might be changed so that the
distracter becomes a more obvious
‘wrong’ or ‘right’ choice. The same
applies for True/False questions where
one question might be rephrased so that
it becomes more obviously
true or not. However, there might be
cases when an item or sometimes a full
task is dropped completely and it is
replaced by another one which in turn
goes through the same series of checks.
The internal
consistency reliability of the test is
maximised by including items that have
large discrimination (“d”) indices. A
common rule of thumb is to
include items that
have discrimination indices equal to or
greater than .30 on a scale of 0.0-1.0.
Distracters are
checked to see whether they performed as
expected. There is a minimum number of
test takers that should select any of
the wrong distracters (Τσοπάνογλου,
2000). If a distracter is not chosen by
any of
the subjects
(or by very few) then this distracter
did not ‘distract’ anyone, therefore it
is replaced with another one. The same
applies for distracters that were chosen
by too many test takers. This means that
the correct answer was not so obvious
(depending on the language level tested)
and then either the malfunctioning
distracter is changed into something
more obviously wrong or the correct
choice is changed into something more
obviously correct.
When this process is
over, the items are ready to be included
in the final test. Before administering
any test, the expected level of
difficulty of the test
as a whole is
checked, and if it does not match our
target, other items are selected, making
sure that these fit in terms of their
content and level of difficulty.
Classical item
analysis has its own limitations. One is
that score statistics obtained from
pre-tests are dependent on the sample
of test takers who take the test. This
means that if we administer the items to
different groups of test takers, the
items may have different statistical
characteristics. This is true for the
administration of the test to the actual
candidates who are a much larger
population with varying characteristics
from period to period. This is why for
every KPG test administration the KPG
team performs post-test item analyses,
to get feedback on the level of
difficulty of the test and on the
internal consistency of the test. These
analyses help improve the reliability of
the test and diagnose why items failed
to function appropriately. Due to the
acknowledged limitations of classical
item analysis, there invariably are
fluctuations in the overall difficulty
level of the administered test and in
its reliability index.
If we take a look at
chart 1 which shows the timeline of the
difficulty index averages for module 1
(reading comprehension) for all levels,
we can see that all administered tests
fell, on average, within a range of .50
to .75. Even though within the tests
themselves one might find items falling
outside this band, this overall average
conforms to the target difficulty index
for all levels and all languages in the KPG examination system which has been
set to fall within range of p= 0.55 to
p=0.80.
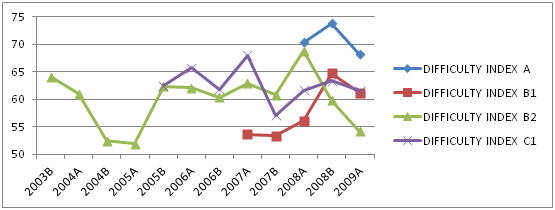
Chart 1: Difficulty Index (p) for
all levels
Chart 2 shows the
average discrimination index for the
items in module 1 for all periods that
each level was administered. We
can see that the trend lines converge on
an average discrimination index of
around .50 demonstrating
a clear upward tendency, which is
considered a quite high discrimination
index that adds to the overall
reliability of the test system.
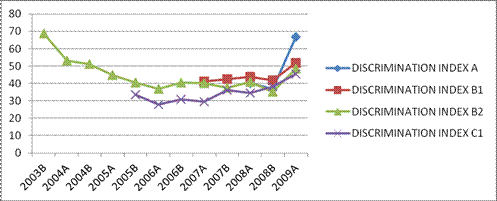
Chart 2:
Discrimination Index (d) for all levels
The reliability of
the test itself is measured through the
Cronbach’s A index and it refers to the
extent to which the test is likely to
produce consistent scores. High
reliability means that students who
answered a given question correctly were
more likely to answer other questions
correctly. Bachman (2004) argues that
high reliability should be demanded in
situations in which a single test score
is used to take major decisions.
One should aim at reliability indices
over .80, especially in large—scale
exams. Chart 3 gives us an indication of
the indices achieved in the reading
comprehension module of the examination
for the B2 level –which is the one
administered for the longest time. All
figures are found in the area over .80,
averaging at .89, which is an index
reflecting a highly reliable test.
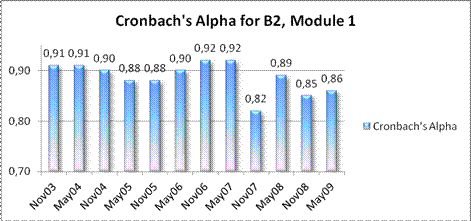
Chart 3: B2
level, Module 1, Reliability Index
All in all, checks
and statistical analyses are performed
both before and after any test is
administered. Pre-testing secures that
the test conforms to the prerequisites
in terms of content and language level,
and post-testing provides us with
feedback on how well (or badly) items
functioned. This feedback is invaluable
as it helps the KPG team shape the test
in terms of level of difficulty and
power of discrimination starting from
the item level through to the task level
until the whole test displays the
characteristics that the KPG examination
board has set.
References
Bachman, L. F.
(2004). Statistical Analyses for
Language Assessment. Cambridge:
Cambridge University
Press
Τσοπάνογλου,
Α. (2000). Μεθοδολογία της Επιστημονικής
Έρευνας και Εφαρμογές της στην
Αξιολόγηση της Γλωσσικής Κατάρτισης.
Θεσσαλονίκη: Εκδόσεις
Ζήτη.
[Back]

